



We are all working remotely with multiple files being shared and myriad login attempts being made from different sources for the various tools that we use. Such activities are often unavoidable and are a necessity for businesses to function smoothly. Let us first talk about credentials. In many organizations, a username and password are present in a table in a database. When someone attempts to log in, the system checks the username and compares the password entered by the user with the one present in the table to check for a match. The most basic password storage format is cleartext where “readable data is stored in the clear”. However, security at this level is nothing much to talk about as it is almost like writing down the credentials in a piece of digital paper which can easily be hacked by hackers. So, you can imagine how vulnerable the system is! The solution? Hashing Algorithm.
What is Hashing Algorithms
Enter hashing algorithm, a fundamental part of cryptography, which refers to “chopping data into smaller, mixed up pieces which makes it difficult for the end user to go back to the original text/state”. A hash function is an algorithm that generates a fixed-length result or hash value from a specific input data. It is different from encryption which converts plain text to encrypted text and with the help of decryption, converts the encrypted text back to the original plain text. In the case of a hashing algorithm, plain text is converted into a hashed text through a cryptographic hash function, thereby making it difficult for hackers to make sense of it. (A hash length of 160 to 512 bits is good). But it doesn’t provide a way to go back to the original text.
So, if we have to ensure password security, hashing ensures that the passwords are hashed and stored in pairs along with usernames in the database table. When one logs in, the password typed is hashed and compared with the hashed entry from the database table. If there is a match, voila! The user is allowed to continue.
Hashtags can be used for password storage, integrity checks, digital signatures, message authentication codes. They can also come in handy for fingerprinting, file transfers, checksums etc.
What makes a Cryptographic Hash Function Ideal?
There are some key aspects that make a hash function ideal for usage.
Hash functions behave as one-way functions
It is impossible to go back to the original text once it has been subjected to a hashing algorithm. So, if you get a specific result, an ideal hash function will ensure that you do not get the initial inputs which lead to the result. For example, 6 divided by 2 gives you a result of 3. But so does 9 divided by 3. But there would be no way to determine the initial two numbers from just the result ‘3’.
Hash functions make use of the avalanche effect very well
A particular input provides a particular output, but even a very minor change in the input (even if very insignificant) will lead to a pretty drastic change in the output.
For example:
Input: App1sealing583
Hash: 5420d1938buif7686dedsf9560bb5087d24676de5f83b7cb4c3b96bf46ec388b
Input: App2sealing583
Hash: 4ic79ff6a81da0b5fc63989d6b6db7dbf1264228052d2da70baqsf7f82961rt6
Hash functions should be fast to compute
For any given input data subjected to hashing, getting results within seconds should not be a problem if the hash function is built strongly
Hash function outputs shouldn’t have any collision
The outputs of two input parameters should never be the same (look at the length of a hash function output and you will get what we are saying)
Hash functions are deterministic
The output of one input parameter has to be the same irrespective of whenever one checks or how many ever times one uses it. This especially comes in handy when multiple people need to be verified at different points in time.
How does the Hashing algorithm work?
Understanding how a hashing algorithm functions can be broken down into a series of straightforward steps, which don’t necessarily require advanced equipment—basic tools and a grasp of mathematics can suffice. However, the use of computers streamlines this process significantly.
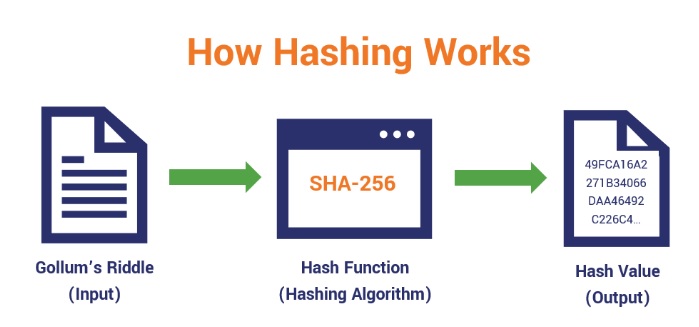

Here’s a simplified explanation of how hashing algorithms typically operate:
Initialization of the Message
Initially, the individual decides on the data or message that needs to be hashed. This could be any form of data, such as a text message or a file.
Selection of the Algorithm
With a multitude of hashing algorithms available, the next step involves selecting the most appropriate one for the task at hand. The choice depends on the specific requirements of the message.
Input of the Message
The selected data is then inputted into a computer that is equipped to run the chosen hashing algorithm.
Execution of the Hash
During this phase, the algorithm processes the input message, which can vary in size, and converts it into a hash of a fixed bit size. This usually involves breaking down the message into smaller, equally-sized blocks that are then individually compressed in a sequential manner.
Output Handling
Finally, the generated hash, also known as the “message digest,” is either transmitted to the intended recipient or stored.
Types of Hashing Algorithms
MD5 (MD stands for Message Digest)
One of the most commonly used yet amongst the most unsecure algorithms. When a password is converted into a specific pattern using this method, it is very easy to simply Google the hash value to get the original value. So, this is best avoided and, in fact, considered unsuitable for further use.
An example:
Input: An example of MD5
Output (Checksum containing 32 digits hexadecimal number like the following): 6c30eeb06ce8eb66b7a65191272b9743
SHA (Secure Hash Algorithm) family of algorithms
SHA-0, introduced in 1993, has been compromised myriad times. SHA-1, though a slightly improved version which has been used for Secure Socket Layer (SSL) security, has also been subjected to many attacks. SHA-2 is now recommended since it is more complicated. SHA-3 can be used by companies who are very serious about security.
An example:
Input: An example of SHA-1
Output: 482ae821c8245e9545e3275cfec2e2657ccab6fb
Whirlpool
It is a 512-bit hash function, derived from Advanced Encryption Standard (AES).
An example:
Input: An example of Whirlpool
Output: 42fefc20dd412b5ad776271d1008ca65d1503a5acd384f3b4e3c8793ded11a0c3d853d721c6d23c37deeecc9b98765575c806099cec4a61b402b65b7a271bfd7
RIPEMD family of algorithms:
It stands for RACE Integrity Primitives Evaluation Message Digest and was developed sometime in the mid-1990s. There are multiple versions like RIPEMD-160, RIPEMD-256 and RIPEMD-320. Since the output lengths keep increasing in the subsequent versions, the security coverage also increases.
An example:
Input: An example of RIPEMD-160
Output: 033432770126267d6640cb35b1d7e1e75a78e7e5
CRC32:
It is known as cyclic redundancy code and is commonly known for its spreading properties. It is also supposed to be a lot quicker leading to smooth file transfers and validations.
An example:
Input: An example of CRC32
Output: 5c8e1a03
Hashing Algorithm’s Security Limitations
Hashing algorithms are secure but are not immune to attackers. At times, a hacker has to provide an input to the hash function which can then be used for authentication. Multiple login attempts through brute force attacks can also be tried out till a match is found.
Since one exact input can have one exact output every single time, a typical, commonly-used password like ‘123456’ will be easier for a hacker to hash and gain unauthorised entry. Also, if multiple users are mapped to the same password, the hacker will be smiling all the way.
Another method called rainbow table attack where a hacker uses a large database of precomputed hash chains to crack passwords is common. Let us talk about the most commonly used password in the world – 123456. Let us consider Md5 hashing function. The way a rainbow table attack will work is as follows:
- Pass the password (123456) through an MD5 hashing function to get: e10adc3949ba59abbe56e057f20f883e
- Pass only the first few characters of the hashed value above (e10adc) to further get another re-hashed value: 96bf38d01b84aa16cf2bb9f55c61ac85
- Repeat the above procedure until enough hashes are obtained in the form of a chain, starting from the initial plain text to the final hashed text
- Store all of them in a table
- Keep going through the list one at a time until a match is found
To counter such attempts, salting technique is used wherein further complexity is added to the hashed value to make it more difficult to crack the password. Here, random data is added to the input of a hash function to generate a much more complex output. Rainbow table mainly works on unsalted hash values, so this adds a further layer of security.
Runtime Application Self-Protection (RASP), which detects attacks on an application in real time, is a good practice to watch out for. With limited human intervention and a smart analysis of contextual behaviour of applications, better security is guaranteed. So, when any suspicious activity is detected, RASP would ensure to terminate a session or provide the relevant alerts to the users for further actions. And they do have an advantage over firewalls which just look at the perimeter of an application and don’t have much of an idea about what is going on inside an application.
What is Collision? How to Handle Collisions?
Since the hashing procedure yields a tiny number for a large key, it is possible for two keys to provide the same result. When a freshly inserted key corresponds to an existing occupied slot, a collision handling technique must be used to address the problem.
Separate Chaining involves handling collisions by linking entries that hash to the same bucket. This method employs a linked list for each bucket in the hash table, allowing multiple records to exist at the same hash function value. While straightforward and effective, this approach requires additional memory for the linked lists outside the main table structure.
Let’s explore how separate chaining works with a practical example, adjusting the numbers for uniqueness in our explanation:
Hash Function: Key modulo 6 (key % 6)
Elements: 13, 16, 23, 26, 38
Following a step-by-step process to resolve collisions:
Initial Setup
Start by preparing an empty hash table designed to accommodate hash values ranging from 0 to 5, based on our hashing algorithm.
First Insertion
For the first key, 13, we apply our hash function: 13%6=1. So, the key 13 is placed in bucket 1.
Handling a Collision
When inserting the next key, 23, we find that 23%6=5, which directs us to bucket 5. If another key had already occupied this bucket, they would coexist by linking the new key to the existing one, thereby forming a chain.
Another Key
For key 16, applying 16%6=4 positions it in bucket 4, assuming no prior occupancy.
Further Collision
With the key 26, we calculate 26%6=2. If bucket 2 is already occupied, separate chaining allows 26 to be added to a linked list originating from bucket 2, effectively resolving the collision.
Through this process, separate chaining facilitates the efficient resolution of hash collisions by utilizing linked lists, ensuring that even with collisions, the data structure remains effective and accessible.
Open Addressing Strategy
Open addressing is a collision resolution technique where all elements are stored directly within the hash table itself, making each slot either occupied by a record or marked as NIL (empty). When inserting or searching for an element, the method involves sequentially probing the hash table until the target element is found or it’s determined the element isn’t in the table.
Methods of Open Addressing
Linear Probing
Linear probing addresses collisions by sequentially searching the hash table from the initial hash position. If the calculated position is taken, the algorithm checks the next slot, continuing until an empty slot is found or the item is located.
Algorithm Steps:
Calculate the initial hash index: index = data % tableSize.
If hashTable[index] is empty, store the data directly at hashTable[index].
If the slot is occupied, move to the next slot using index = (index + 1) % tableSize until an empty slot is found.
Repeat the process until a suitable slot for the data is identified.
Example: For a hash function of “key modulo 6”, inserting keys like 51, 71, 77, 86, and 94:
Create an empty hash table for hash values between 0 and 5.
For key 51, since 51%6=3, place it in slot 3.
Key 71 would also map to slot 3 (71%6=5), but since slot 3 is taken, it moves to the next available slot.
Quadratic Probing
Quadratic probing resolves hash collisions by adding squared increments to the initial index (quadratic polynomial increments), offering a more distributed approach to probing compared to linear probing.
Algorithm Steps:
Start with the initial hash index: hash(x) % n.
If that slot is taken, try (hash(x) + 1^2) % n, and if that’s also full, try (hash(x) + 2^2) % n, continuing this pattern.
Repeat this process until an empty slot is found for the data.
Example: With a table size of 7 and hash(x) = x%7:
To insert 25, 31, and 50, start with hash(25) = 25%7=4. Slot 4 is empty, so 25 goes there.
Inserting 50, hash(50) = 50%7=1. If slot 1 is occupied, check slot 2 (1+1^2), then slot 5 (1+2^2), until an empty slot is found.
Load Factor in Hashing
The load factor is a critical metric in hashing, defined as the ratio of the number of entries in the hash table to the hash table’s size. It is a key indicator of the hash table’s efficiency and performance, guiding decisions on when to resize or rehash the table. A low load factor means fewer entries per index, aiming for an operational complexity close to O(1), which is ideal for maintaining fast access times in a hash table.
Final Thoughts
Even though newer versions of hashing algorithms are introduced in the market with an added layer of security and SHA-2 does seem to be a good option out there, it is always better to be updated with the latest in the hashing algorithm technology.
But definitely when it comes to business continuity where credential verification and file/message transfers are an on-going activity across the world, hashing algorithms do the job well.
To secure your javascript code without ANY CODING from reverse engineering and tampering attacks, click on the link below to know more about AppSealing and sign-up for a free trial.
Frequently Asked Questions
1. Is AES a hashing algorithm?
AES is not a hashing algorithm. AES is an encryption standard used to protect electronic data. It is a block cipher that encrypts data in blocks of 128 bits each. It is a symmetric algorithm that uses the same key for encryption and decryption.
2. Is RSA a hashing algorithm?
RSA is an asymmetric encryption algorithm that uses two different keys to encrypt and decrypt data. RSA keys are 1024-bits or 2048-bits long.
3. What is MD5 and SHA256?
The MD5 (Message-Digest algorithm) is a hashing algorithm that generates a 128-bit digest. It ensures that the file remains unaltered by producing and comparing checksums for both sets of data. However, it is no longer considered a secure hashing method. SHA256 stands for Secure Hash Algorithm 256-bit which is an irreversible hash function. It is used for secure password hashing and resists brute force attacks.
4. What are the 3 types of the hash collision algorithms?
CRC-32, MD5, and SHA-1 are the three types of hash algorithm that have varying levels of collision risk. CRC-32 poses the highest risk for collision whereas SHA-1 presents the lowest risk.
5. Which hash algorithm is fastest?
SHA-1 is the fastest hashing algorithm that delivers ~587.9 ms per 1M operations for short strings and 881.7 ms per 1M for longer strings.
6. How many types of hashing are there?
MD5, SHA-2 and CRC32 are the three important types of hashing used for file integrity checks. MD5 encodes information into 128-bit fingerprints and is used as a checksum. SHA-2 has hash functions with values of 224, 256, 384 or 512 bits. CRC is used to identify accidental changes to data. Common areas of application for CRC32 include ZIP files and FTP servers.
7. What is a hashing algorithm?
A hashing algorithm is a special mathematical function that converts data into a fixed-length string of letters and numbers known as a hash value. It is designed to efficiently store and retrieve data, and to protect data at rest by making it unreadable. Hashing algorithms are one-way, meaning the original data cannot be unscrambled or decoded.
8. How does a hashing algorithm work?
A hashing algorithm converts data into a fixed-length string of letters and numbers using a special function. It breaks the input data into blocks, then applies the hashing process to each block. The resulting hash values are used to efficiently find or store items. Hash collisions, where two different inputs produce the same hash value, can occur but are minimized by the algorithm’s design. Hashing can also be used to authenticate data.
9. What are the common types of hashing algorithms?
Common types of hashing algorithms used for various purposes like data retrieval, integrity verification, and secure data storage include MD5, SHA-2, and CRC32. These algorithms are used to authenticate data and ensure that the data is genuine by generating a hash and comparing it to the original. Hash collisions can be intentionally created for many hash algorithms, but the probability depends on the algorithm size and distribution of hash values.
10. What is the purpose of using a hashing algorithm?
Hashing is used to convert data into a fixed-length string of characters called a “hash value.” It is designed to efficiently find or store an item in a collection, making data retrieval quicker than searching in lists and arrays. Hashing provides a more secure and adjustable method of retrieving data compared to other data structures.
11. Can a hashing algorithm be reversed?
Hashing algorithms are designed to be computationally irreversible, making it extremely difficult to reverse the process and obtain the original input from the hash output. This property is crucial for ensuring data security and integrity in information systems.